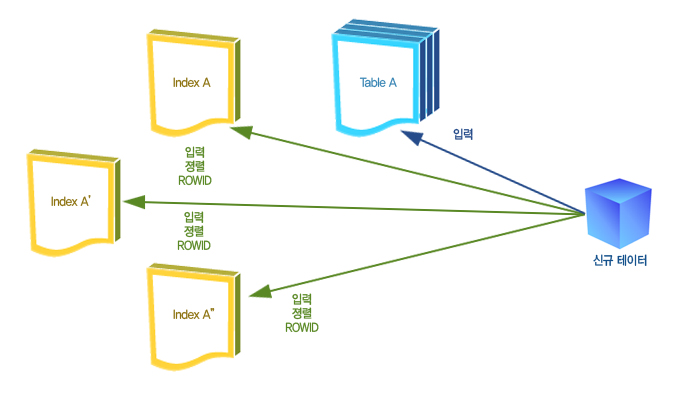
Index의 종류 Index의 종류 |
|
| create [unique|fulltext|spatial] index index_name [index_type] |
on tbl_name (index_col_name,...)
|
| index_col_name: |
col_name [(length)]
|
| index_type: |
using {btree | hash}
|
| - 사용예: mysql> create index id_index using btree on lookup (id); |
| - []는 지정하지 않아도 된다는 것을 의미함. |
|
|
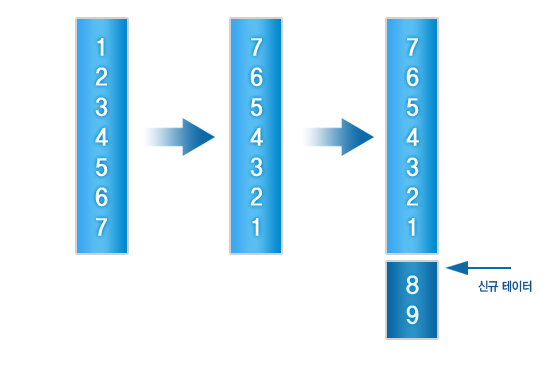
Index 생성 시 index_type을 지정하지 않으면 BTREE가 기본 Index로 지정된다.
|
② 부분 Index(Partial Index)
|
| ㉮ mysql > create index part_of_name on customer (name); |
| ㉯ mysql > create index part_of_name on customer (name(10)); |
|
|
㉮와 같이 Index를 생성하면 name의 모든 크기가 Index로 생성이 되나 ㉯처럼 생성할 경우 name의 처음 10자를 이용하여 Index를 생성한다. 만약 200만명 회원의 영문이름을 8자만을 이용하여 Index를 생성해도 약 16GB의 물리적 공간이 필요하다. 이 경우 부분 Index를 생성하면 전체적인 물리적 공간이 줄어 데이터 입력 시 속도가 보다 빠르다.
|
| mysql > alter table phone_book add index (last_name(4)); |
| mysql > select * from phone_book where last_name = 'Smith'; |
|
|
위와 같이 부분 Index를 생성 시 Optimizer는 Smit 영문을 사용하여 Index를 검색하게 된다. Smith, Smitty 등은 모두 Smit Index를 사용하여 테이블을 검색하게 되며 이때 Index에서 테이블로의 랜덤액세스(Random Access)가 발생하게 된다.
|
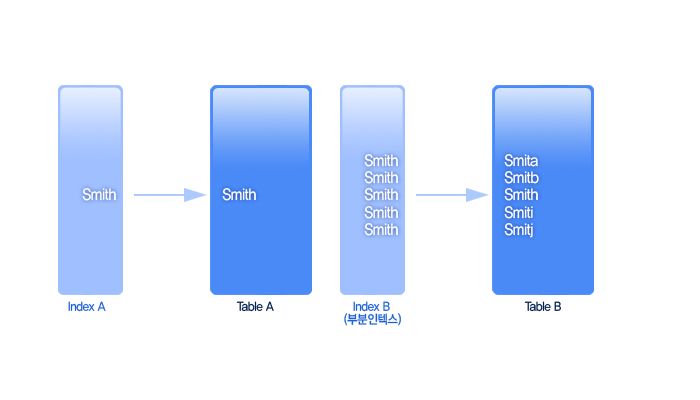 |
즉, Smith 철자로 Index가 구성되면 딱 1번의 테이블 액세스가 발생하지만 Smit 철자를 이용할 경우 Index에 다수의 Smit가 생성되어 속도저하의 원인이 될 수 있다. 이런 형태의 Index를 생성하는 경우는 대량메일시스템의 이메일 리스트처럼 대량 의 메일주소가 입력되어 파일사이즈를 절약하면서도 속도가 그렇게 중요한 요소가 아닌 페이지에 적합하다.
|
|
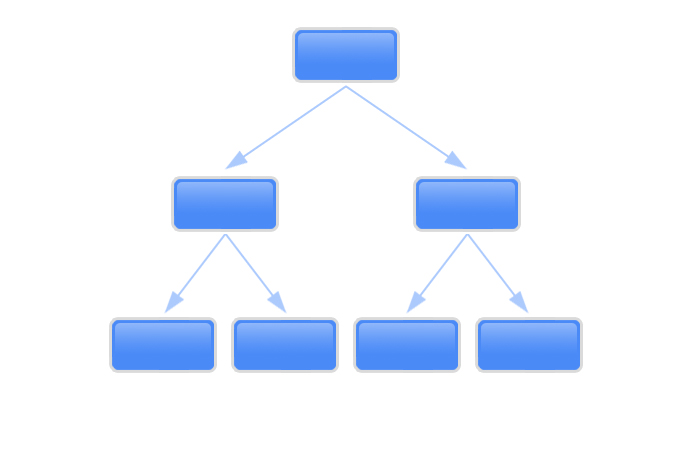
하나의 컬럼으로 만든 Index를 싱글 Index라고 한다면 2개 이상의 컬럼으로 만든 Index를 결합 Index 또는 복합 Index라고 한다.
|
| mysql> alter table phone_book add index (last_name, first_name); |
| mysql> select * from phone_book |
| -> where last_name = 'Woodward' |
| -> and first_name = 'Josh'; |
|
|
Optimizer는 하나의 SQL에서 테이블당 오직 하나의 Index만을 사용할 수 있다.(단, UNION은 예외) 따라서 동시에 조건을 만족해야 하는 경우에 결합 Index를 사용하면 테이블 액세스를 줄여줘 성능을 향상시킬 수 있다.
|
| mysql > select * from tab1 where col1 = 'A' and col2 between 113 and 115; |
|
|
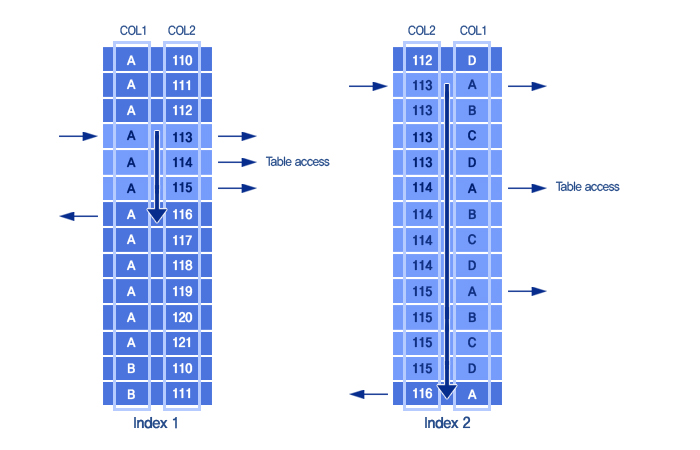 |
▶ 결합 Index를 Index1: COL1 + COL2로 구성했을 때
- B-Tree 방식으로 COL1 = A이고 COL2 = 113인 첫 번째 Row를 바로 찾는다.
- ROWID를 이용하여 테이블의 Row를 액세스한다.
- 다음 Row를 차례로 스캔하면서 COL1이 A가 아니거나 COL2가 115보다 클 때까지
테이블의 Row를 액세스하고 그렇지 않으면 처리를 종료한다.
▶ 결합 Index를 Index2: COL2 + COL1로 구성했을 때
- B-Tree 방식으로 COL2 = 113이고 COL1 = A인 첫 번째 Row를 바로 찾는다.
- ROWID를 이용하여 테이블의 Row를 액세스한다.
- COL2가 115보다 큰 값이 나올 때까지 계속해서 스캔한다. 스캔한 Row는 COL1이
A인지를 체크하여 성공하면 ROWID를 이용하여 테이블을 액세스한다.
- COL2가 115보다 커지면 처리를 종료한다.
결합 Index는 선행 컬럼이 =로 사용되지 않으면 뒤에 있는 컬럼이 비록 =을 사용하더라도처리범위는 줄어들지 않는다.
이것은 결합 Index의 컬럼 순서를 결정하는 매우 중요한 요소가 된다.
첫 번째 컬럼과 두 번째 컬럼만의 문제가 아니라 어떤 위치에 있는 컬럼이든지 자기보다 앞에 있는 컬럼이 =로
사용되지 않으면 자신의 역할은 단순한 체크기능으로 전락하고 전혀 범위를 줄여주는 역할을 할 수 없다.
|